


Predictive analytics. The phrase itself sounds a little intimidating, doesn't it? It conjures up images of complex algorithms and impenetrable math. But at its core, it's about something deeply human: using the data you already have to make sharp, educated guesses about the future. It's the engine that combines machine learning and good old statistical modeling to find patterns hidden in plain sight. The real goal? To move your business from constantly putting out fires to preventing them in the first place.
When Guessing Is No Longer a Viable Strategy
It usually starts with a question that just will not go away. Why did sales crater last quarter? What's driving this spike in customer churn? This is the moment so many teams hit—drowning in spreadsheets, hunting for an answer that feels just out of reach.
I had a client in this exact spot. Their customer retention numbers were a total black box. Month after month, a chunk of their user base would just vanish, and they had no clue why. More importantly, they had no way of knowing who was on the chopping block next. Their entire strategy was reactive, a constant, exhausting cycle of damage control.

The Breaking Point
Their old method was a mess of manual report exports, pivot table madness, and endless meetings where everyone threw a different theory at the wall. It was guesswork, pure and simple. They were fighting fires without ever figuring out what was causing the sparks.
That struggle became the push they needed to find a better way. They had to stop guessing and start anticipating. This is where predictive analysis machine learning came into the conversation, not as some far off tech buzzword, but as a practical fix for a very real, painful problem. A perfect example of where this moves beyond theory is in customer churn prediction.
The real power here is not in the complex math; it is in turning raw uncertainty into something you can actually act on. It's about building a system that can see around the corner for you.
This is a journey from a defensive crouch to a proactive, data informed strategy. In this guide, we will walk through exactly how to build that system. You will see that predictive analytics is less about intimidating algorithms and more about the fundamental need to know what is coming next.
Understanding Predictive Analysis and Machine Learning
Let us pause for a moment and cut through the noise. At its core, predictive analysis machine learning is all about teaching a computer to be a seasoned detective. It learns to comb through mountains of past evidence—your data—to spot hidden patterns and make incredibly sharp guesses about what is coming next. You are essentially giving it years of experience in an instant, without all the painful trial and error.

Think about how meteorologists forecast the weather. They do not just guess; they analyze historical data on temperature, humidity, and wind patterns to predict whether you will need an umbrella tomorrow. A machine learning model does the exact same thing with your business data, using things like customer purchase history or website clicks to forecast future outcomes.
The Core Building Blocks
To really get a handle on this, you only need to grasp a few key ideas. Let us forget the dense mathematics for a second and think of it like baking a cake. You need your ingredients, a recipe, and an oven to bring it all together.
- Training Data (The Ingredients): This is all your historical data, the raw material for your project. It's a complete record of everything that has happened in the past, from every single sale down to each customer support ticket.
- Features (The Specific Ingredients): These are the individual data points that the model actually learns from. If you are trying to predict sales, your features might include the day of the week, how much you spent on marketing, or if a promotion was running.
- Model (The Recipe): The model is simply the algorithm—the set of rules—the computer uses to mix the features together and spit out a prediction. It's the recipe that learns the relationship between your ingredients to create the final cake.
The whole point here is to show that anyone can understand the thinking behind this powerful technology. We are not building some mysterious black box; we are giving the machine a rulebook based on cold, hard evidence from the real world.
The magic is not in some futuristic AI taking over. It is in a well trained system that has learned from every success and failure in your data's history. It just happens to have a perfect memory and the power to connect dots we might otherwise miss.
This is not just theory; it is already reshaping business strategy on a global scale. The predictive analytics market, which is massively driven by machine learning, was valued at around USD 18.9 billion in 2024. It's projected to explode to USD 82.35 billion by 2030. That staggering growth, a compound annual growth rate of 28.3%, tells you just how many organizations are ditching guesswork for data driven forecasting.
As you start exploring this field, you will see just how many doors it opens. In fact, we've put together a list of https://kdpisda.in/10-powerful-artificial-intelligence-ideas-ready-for-2025/ that are built on these very principles. And if you want to go a layer deeper into the infrastructure making it all possible, check out these resources on how networks are powering the next generation of AI agents.
Why Your Data Is the Hero of the Story
Every predictive model has a hero, and it is not some fancy algorithm—it's your data. It is easy to get caught up in the excitement of complex models, but here is the honest truth: a predictive model is only as smart as the information it learns from. If you treat data preparation like a tedious chore, you are guaranteed mediocre results. But if you treat it like the most critical chapter of your story, you will build something genuinely powerful.
The journey starts with gathering your raw materials. Your data might be scattered across different databases, spreadsheets, or even third party APIs. The first step is simply bringing it all together in one place, setting the stage for the story to unfold.
Once you have your data, you hit the messy part: cleaning it up. This is where the real detective work begins. You will be dealing with missing values, correcting bizarre outliers, and fixing all sorts of inconsistencies. I once spent a full week hunting down a critical bug in a model, only to find it was caused by a single, misplaced comma in a CSV file. It's a humbling reminder that the smallest details matter.
The Art of Feature Engineering
After the initial cleanup, we get to one of the most creative parts of the process: feature engineering. This is the art of transforming raw, often chaotic data into meaningful signals—or 'features'—that your model can actually understand. Think of it as giving your detective a set of perfectly organized, high quality clues instead of just a jumbled box of evidence.
For instance, raw timestamps of customer purchases are not very useful on their own. But through feature engineering, you can transform them into valuable signals like:
- Day of the Week: Are customers more likely to buy on weekends?
- Time Since Last Purchase: How long has it been since a customer last bought something?
- Purchase Frequency: How many times has a customer made a purchase in the last month?
Each of these engineered features tells a much richer story than a simple timestamp ever could. This process demands a mix of domain knowledge and creativity. You have to start thinking like the model, asking yourself, "What information would actually help me make a better prediction?" Effectively tracking the impact of these new features is a discipline in itself, much like the structured approach detailed in this guide to engineering productivity measurement.
This visualization shows a simple decision tree to check if your data is ready for the next step.
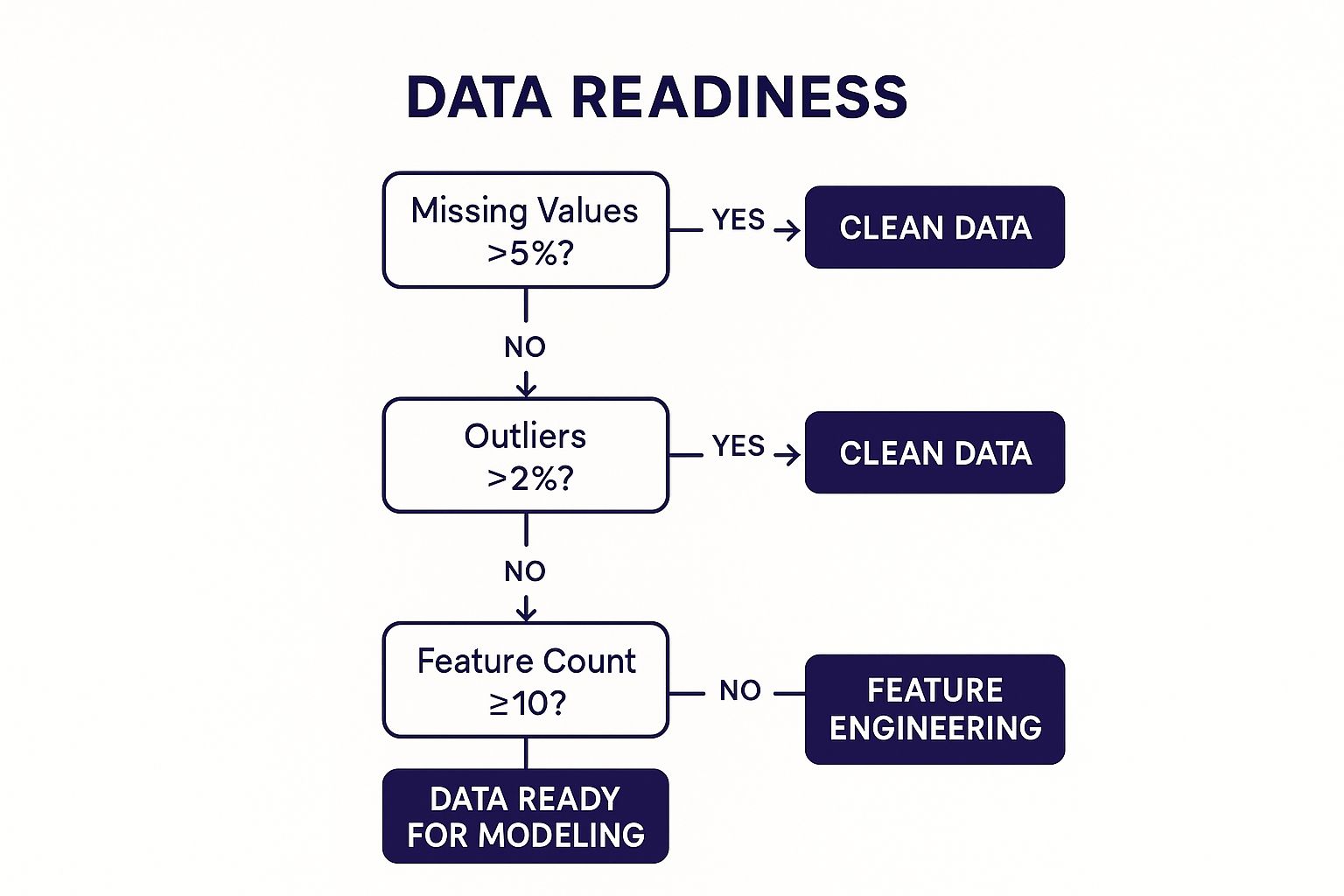
The tree guides you through key checks like missing values and outliers before deciding if you are ready for modeling or need more feature engineering.
A Real World Example: Customer Churn
Let us make this concrete with our customer churn example. Imagine we have a raw dataset with the following columns: CustomerID, LastLoginDate, SubscriptionPlan, and TotalSpent. It is a decent start, but we can do a lot better.
Step 1: Data Gathering and Cleaning
First, we pull all this data into a single table. We immediately notice some customers have no LastLoginDate. Do we delete them? Or can we fill that gap, maybe with their sign up date? We decide to fill it, making a careful note of our assumption. We also scan the TotalSpent column for any strange values, like negative numbers, and fix them.
Step 2: Feature Engineering
Now, we get creative. From our simple dataset, we can engineer several new features that tell a story about customer engagement and value:
- AccountAge (in days): CurrentDate minus SignUpDate.
- Recency (in days): CurrentDate minus LastLoginDate.
- AverageMonthlySpend: TotalSpent divided by AccountAge in months.
- IsPremiumPlan: A simple binary (1 or 0) flag indicating if they are on a premium plan.
With just a few transformations, we've turned four simple columns into a much more descriptive profile of each customer. We have not added new information, but we have made the existing information far more insightful.
Step 3: Getting Model Ready
Finally, we need to prepare this cleaned, feature rich dataset for the model. Machine learning models work with numbers, not text. This means converting categorical data, like the SubscriptionPlan name, into a numerical format through a process called one hot encoding.
After this final step, our chaotic dataset is now a clean, structured foundation. It's model ready, poised to deliver the powerful insights we've been looking for. Your data hero has completed its origin story.
Choosing the Right Predictive Algorithm
Alright, let us pause and reflect. Your data is clean and ready for action. Now the next big question is which tool to pull from your digital toolbox. Stepping into the world of predictive analysis machine learning algorithms can feel a bit like walking into a massive, unfamiliar workshop. You are surrounded by dozens of powerful, complex looking tools, and it's not always obvious which one is right for the job.
The reality is, not all prediction problems are built the same, and picking the right algorithm is a blend of knowing your data and a bit of practical wisdom. You do not need a PhD in applied mathematics to make a smart choice; you just need to get really clear on the problem you are trying to solve. Let us walk through the most common algorithms, treating them like the trusted, specialized tools they are.
This whole field is seeing explosive growth for a reason—these tools are becoming more accessible and more powerful every day. Industry forecasts predict the predictive analytics market will balloon from USD 22.2 billion in 2025 to an incredible USD 91.9 billion by 2032. This surge, especially in areas like finance and insurance, just goes to show how critical it is to match the right algorithm to your specific business challenge.
Your Go To Tools for Prediction
Think of these algorithms as different specialists you can call on. Each one has a unique skill set and is perfectly suited for a certain type of task.
- Linear Regression: This is your reliable, straightforward workhorse. If you need to predict a continuous number—like next quarter's sales figures, the price of a house, or how many users will visit your site—Linear Regression is often the perfect place to start. It works by finding a simple, straight line relationship between your inputs and the number you want to predict.
- Logistic Regression: Do not let the name fool you; its job is actually quite simple. Logistic Regression is like the cousin of Linear Regression, but it specializes in answering "yes" or "no" questions. Will a customer churn? Is this email spam? Will a user click on this ad? It calculates a probability, giving you a clear signal for binary outcomes.
- Decision Trees: If you need an algorithm that is incredibly easy to understand and explain to your non technical colleagues, the Decision Tree is your champion. It works just like a flowchart, asking a series of simple questions about your data to arrive at a final prediction. Its visual nature makes it a fantastic tool when transparency is key.
Of course, while these are the foundational building blocks, the field is constantly moving forward. For instance, advanced techniques like those in our guide on Retrieval-Augmented Generation, the secret sauce for smarter AI, are continually pushing the boundaries of what is possible.
Making the Right Choice
So, how do you actually pick your champion? The decision usually comes down to balancing a few key factors. It is not about finding the most "powerful" model, but rather the most appropriate one for your situation.
The best model is not always the most complex one. Often, the simplest model that effectively solves your problem is the right choice because it is easier to build, debug, and explain.
To make things a bit clearer, here's a quick glance table comparing these workhorse algorithms. Think of it as a cheat sheet for your predictive modeling toolkit.
Choosing Your Predictive Algorithm
| Algorithm | Best For Predicting... | Key Strength | Potential Pitfall |
|---|---|---|---|
| Linear Regression | Continuous numerical values (e.g., price, sales) | Simplicity and high interpretability. | Assumes a linear relationship in the data, which is not always true. |
| Logistic Regression | Binary outcomes (e.g., yes/no, churn/no churn) | Very efficient and easy to implement. | Can struggle with complex, non linear relationships. |
| Decision Trees | Both classification and regression tasks | Highly intuitive and visual; handles non linear data well. | Prone to "overfitting," where it learns the training data too perfectly. |
Ultimately, choosing an algorithm is a crucial checkpoint in your predictive analysis machine learning journey. The best first step is always to clearly define your problem. Are you trying to predict a number or a category? How important is it that you can explain the model's reasoning? Answering these questions first will naturally guide you to the right tool and set you up for success down the road.
The Moment of Truth: Is Your Model Actually Any Good?
You've built your predictive model. It's an exciting moment. The data is clean, the algorithm is humming, and the first predictions are rolling in. Now for the hard part—the moment of truth. Is this thing actually any good?
This is where the art of model evaluation kicks in. It is a classic rookie mistake to just chase a single metric like "accuracy." I mean, who would not be thrilled with a model that is 95% accurate? It sounds fantastic, but that number can be dangerously misleading, especially when your data is not perfectly balanced.
Let me give you a real world example. Imagine you are building a model to spot a rare disease that only hits 1% of the population. A lazy model could just predict "no disease" for every single person and hit 99% accuracy. It's technically right almost all the time, but it is completely useless. It fails at its one critical job: finding the people who are actually sick. This is why we have to dig deeper.
Beyond Simple Accuracy
To really get a feel for our model's performance, we need to ask better questions. Think of it like a medical test. A test can be wrong in two very different ways, and the consequences of each are worlds apart.
- False Positive: The test says you have the disease, but you don't. This leads to a lot of unnecessary stress and maybe a few more tests, but it is usually manageable.
- False Negative: The test says you are fine, but you are actually sick. This is the big one. It is a far more dangerous mistake because a serious condition goes completely untreated.
In the world of predictive analysis machine learning, we measure these scenarios with precision and recall. Precision asks, "Of all the times we predicted 'yes,' how often were we actually right?" Recall, on the other hand, asks, "Of all the actual 'yes' cases out there, how many did our model manage to find?"
Which one matters more? That depends entirely on the problem you are trying to solve. For something like a spam filter, a false positive (a real email landing in your spam folder) is way more annoying than a false negative (a single spam email getting through). But for fraud detection, a false negative (missing a fraudulent transaction) could be an absolute disaster.
The Unbiased Judge: A Validation Set
There's one last piece to this puzzle, and it is critical. A model can get really good at "memorizing" the training data it learns from. It is like a student who crams for a test—they can spit back answers but do not truly understand the material. To stop this from happening, we hold back a chunk of our data called a validation set.
This validation set acts as an unbiased judge. The model has never seen this data before, so its performance on this set gives us a true, honest measure of how well it can generalize to new, unseen information.
This kind of rigorous evaluation is what separates a fun academic project from a reliable system you can bet your business on. It is also why this field is exploding. The global market for predictive analytics is projected to grow from USD 14.4 billion in 2024 to over USD 100 billion by 2034, all driven by the real world value of trustworthy decisions. You can dive deeper into this incredible market growth in recent industry reports.
Getting evaluation right is not just a technical step; it's the foundation for building real trust in what your model has to say.
Key Takeaways from Our Journey
We have covered a lot of ground together, have not we? We started with a nagging business problem and worked our way through gathering the data, picking the right tools, and—most importantly—asking the hard questions to see if our model was actually any good. This whole process, from start to finish, is the real heart of predictive analysis machine learning.
Before you dive headfirst into your own projects, let us hit pause and really lock in the big lessons from this journey. Think of this as your pre flight checklist.
Your Core Predictive Analysis Checklist
This is not just a recap. These are the non negotiable rules that make the difference between a successful project and one that spirals into endless debugging. I learned some of these the hard way so you do not have to.
- Your Data Is Everything: You can have the most brilliant algorithm in the world, but if you feed it messy, incomplete data, you'll get garbage out. The time you spend cleaning your data, truly understanding it, and engineering new features is the single best investment you can make. Do not you dare skip it.
- Choose the Right Tool for the Job: Do not get hypnotized by the most complex algorithm you can find. A simple Linear Regression model that you can actually explain to your team is infinitely more valuable than a deep learning beast no one understands. Your goal is to solve a business problem, not win a science fair.
- Honest Evaluation Builds Trust: A model's true worth is proven only on data it has never seen before. Metrics like precision and recall, backed by a solid validation set, are how you build real confidence. An 85% accurate model you understand inside and out is far better than a 99% accurate model that is a total black box.
The goal is not just to build a model. It is to build a reliable system that delivers real world value. That reliability is born from diligent data work, pragmatic choices, and ruthless honesty during evaluation.
Where Do You Go From Here?
This is not the end of the road; it is the launchpad. You now have a solid framework for thinking through predictive problems. From here, your adventure can branch out in a few exciting directions.
- Explore More Advanced Models: Now that you have got the fundamentals down, you can start checking out more powerful algorithms. Look into things like Random Forests or Gradient Boosting, which can often squeeze out better performance.
- Learn About Model Deployment: Building a model is one thing, but getting it into a live production environment to make real time predictions is a whole different ballgame. This is where your creation starts delivering non stop value.
- Start Your Own Project: Seriously, the best way to learn is by doing. Find a small, well defined problem in your business or grab a public dataset and just walk through the steps we covered. Your first project will teach you more than a dozen articles ever could.
Consider this your official invitation to take what you have learned and start making things happen. Your journey into predictive analysis has just begun.
Got Questions? Let's Get Them Answered.
As you start digging into predictive machine learning, a few common questions always seem to surface. It is totally normal. Let us walk through some of the biggest ones I hear all the time to clear things up.
What's the Real Difference Between Predictive and Prescriptive Analytics?
This question gets right to the heart of what you are trying to accomplish with your model. It's a great one.
Think of predictive analytics as a seasoned weather forecaster. They look at all the historical data, the current conditions, and tell you, "There's a 90% chance of rain tomorrow." It gives you a smart, data backed guess about what is likely to happen next.
Prescriptive analytics, on the other hand, is your GPS seeing that forecast and the live traffic data, then telling you, "Leave 15 minutes early and take the highway to avoid the storm and the inevitable traffic jam." It does not just predict a problem; it tells you exactly what to do to get the best outcome.
So, predictive tells you what might happen. Prescriptive tells you what you should do about it.
How Much Data Do I Actually Need to Build a Good Model?
This is the classic "it depends" question, but let me give you a more useful answer. It's less about the sheer volume and far more about the quality and relevance of your data.
A model trained on 1,000 clean, high quality, and representative records will almost always crush a model trained on a million messy, irrelevant data points. The question you should be asking is: "Does my data have enough examples of the outcome I want to predict?"
For instance, if you are trying to predict customer churn but your dataset only has ten examples of customers who actually left, your model is going to have a brutal time learning the pattern. A decent rule of thumb is to have at least a few hundred examples of the specific outcome you're targeting.
The goal is not to find the biggest dataset possible. It is to find the richest one—a dataset that tells the true story of the problem you are trying to solve.
Can a Predictive Model Ever Be 100% Accurate?
In a single word: no. And honestly, you should be wary of any model that claims to be.
Chasing 100% accuracy is a massive red flag for a common problem called overfitting. This is where the model has not learned the general patterns in your data; it has basically just memorized the training set, noise and all. This kind of model looks like a genius on the data it is already seen but will fall flat on its face when it encounters new, real world data.
The world is messy and full of random events that no amount of historical data can fully account for. The point of predictive analysis machine learning is not to build a flawless crystal ball. The goal is to build a tool that drastically reduces uncertainty and helps you make better, more informed decisions than you could without it.
Ready to move from theory to execution? As a full stack engineering consultant, Kuldeep Pisda helps startups build robust, scalable systems and integrate AI driven features that deliver real business value. Let's build something powerful together. Learn more at kdpisda.in.
Subscribe to our newsletter.
Become a subscriber receive the latest updates in your inbox.
Member discussion