

Let's be honest. Event driven architecture can sound like one of those buzzwords engineers throw around to sound smart. But it's not just jargon; it's a totally different way of thinking about how the parts of your application talk to each other. I remember the first time I really got it, it felt like a lightbulb moment.
Instead of services directly calling each other and waiting for a response (the digital equivalent of being put on hold), they just announce things that have happened. "Hey, a new user signed up!" Other services that care can listen in and react. This creates systems that are incredibly decoupled, scalable, and way more resilient to the chaos of the real world.
Moving Beyond the Monolithic Traffic Jam
You know that late night call, right? The one where a tiny glitch in the payment gateway cascaded, bringing your entire e commerce platform to its knees during a flash sale. I've been there. That feeling of utter helplessness is a classic symptom of tightly coupled, monolithic systems. It's like every single component is stuck in the same massive traffic jam.
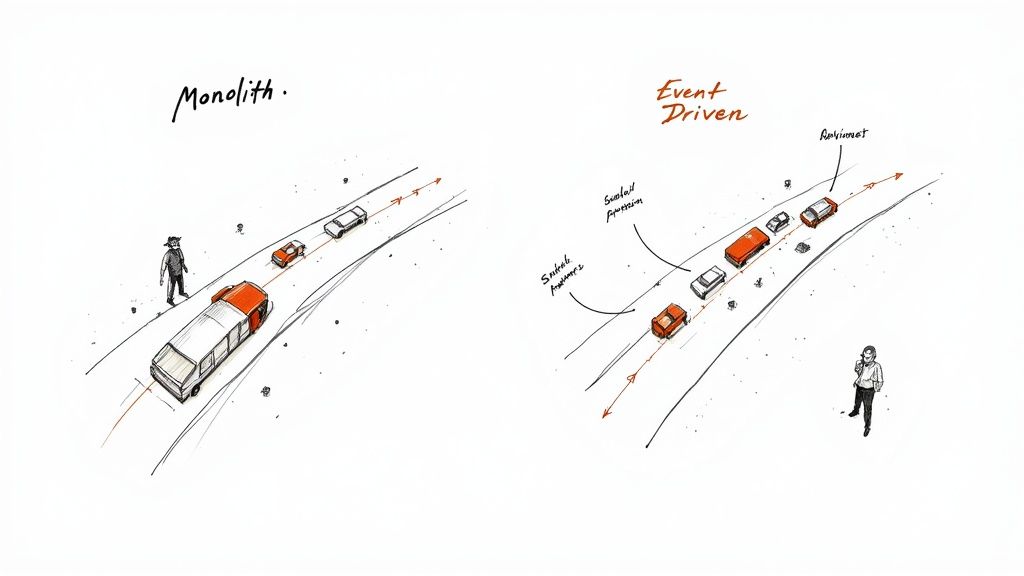
The Problem with Waiting in Line
In a traditional, synchronous world, services are constantly making direct requests and then just... waiting. The "Orders" service calls the "Inventory" service and holds its breath, completely blocked until it gets a confirmation. If that Inventory service is slow or, heaven forbid, down, the entire order process grinds to a halt.
This is the monolithic traffic jam in action. A single stalled car blocks the entire highway. This design is fragile. A failure in a non essential part of the system, like a notification service, can completely prevent a core function, like processing an order, from ever finishing.
A Better Way Forward
Event driven architecture offers a practical escape route from this brittleness. The whole philosophy is a shift from those direct, synchronous calls to a world of decoupled, asynchronous communication. It's a fundamental change in how your services interact.
Instead of calling the Inventory service directly, the Orders service simply announces a fact: "An order was created." It publishes this event and immediately moves on with its life, completely unaware of who might be listening. Other services—like Inventory, Shipping, and Notifications—can subscribe to this "OrderCreated" event and react independently, often all at the same time.
This simple change has profound implications for your system:
- Resilience: If the Notifications service is down, who cares? The order still gets processed. Inventory is still updated. The system bends without breaking.
- Scalability: You can spin up a new fraud detection service that just listens for "OrderCreated" events without ever having to touch or redeploy the original Orders service.
- Flexibility: Individual services can be updated, deployed, or scaled on their own schedules. This autonomy is a cornerstone of modern system design and a key tenet of building effective microservices. If you want to go deeper on this, check out our guide on microservices architecture best practices for 2025.
This isn't just theory; it's about understanding why this shift is so critical for building modern, robust applications. The goal is to move from a system where everything waits in line to one where components work together without being chained to each other.
Learning the Language of Events
Before we start wiring up complex systems, we need a shared vocabulary. Stepping into event driven architecture is a bit like learning a new language—one built on announcements and reactions rather than direct commands.
Get these three core concepts down, and you'll have the foundation for everything that follows.
This shift in thinking is gaining massive traction. Today, around 85% of organizations recognize the business value of event driven systems, using them to handle everything from real time user notifications to massive data processing pipelines. Giants like Netflix and Uber rely on these principles to stay responsive at a global scale.
But it's a journey. Only about 13% of businesses feel they have fully mastered this approach, which shows just how much room there is to grow and learn. You can explore more about how backend systems are evolving at nucamp.co.
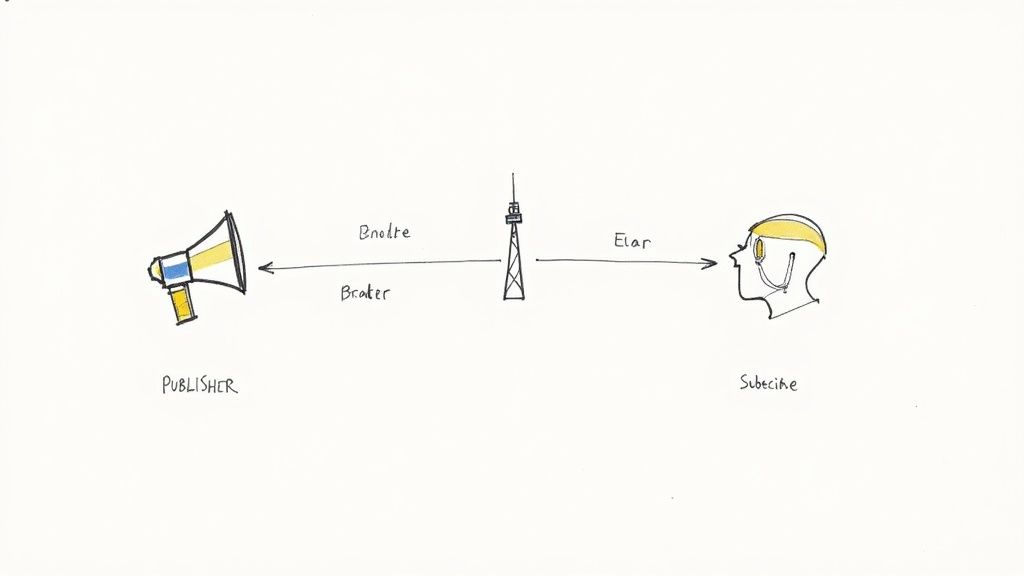
Meet the Key Players
At the heart of any event driven system, you'll find three main roles. Understanding their distinct responsibilities is the first step toward appreciating the elegance of this architectural style.
To make this crystal clear, here's a quick breakdown of the key players and their roles in the system.
Key Roles in an Event Driven System
| Component | Role | Analogy | Example Technology |
|---|---|---|---|
| Publisher | The event producer. Broadcasts a message when something happens. | A news reporter announcing a breaking story. | A UserService sending a UserCreated event. |
| Subscriber | The event consumer. Listens for specific messages it cares about. | A reader who only follows the sports section. | An EmailService listening for UserCreated. |
| Event Broker | The message router. Receives messages and delivers them to subscribers. | The central post office sorting and delivering mail. | RabbitMQ, Apache Kafka, or AWS SQS. |
This table gives you a mental model for how information flows without direct connections. Let's dig into each role a bit more.
- The Publisher: This is any component that has something interesting to say. When a user creates an account, the user service becomes a publisher. It broadcasts a simple fact: "UserCreated." Crucially, it has no idea who, if anyone, is listening. It just shouts its news into the void and moves on.
- The Subscriber: This component tunes in to specific broadcasts it cares about. The email service might subscribe to "UserCreated" events to send a welcome message. The analytics service might also subscribe to the same event to update its user count. Each subscriber acts independently, reacting to the event in its own way.
- The Event Broker: This is the central communication hub—the radio tower in our analogy. It's middleware like RabbitMQ, Apache Kafka, or AWS SQS. The broker's job is to receive events from publishers and reliably deliver them to all interested subscribers. It also acts as a buffer, ensuring messages aren't lost even if a subscriber is temporarily offline.
This separation of concerns is the secret sauce. The publisher is completely decoupled from the subscribers. You can add a new subscriber—say, a fraud detection service—without ever touching the original user service. This is what gives these systems their incredible flexibility and resilience.
This principle of clear contracts between services is also fundamental to good API design. You can learn more about that in our guide on API documentation best practices for 2025.
The magic of event driven architecture patterns lies in this fundamental decoupling. Publishers announce, subscribers react, and the broker ensures the message gets through. This simple model allows complex systems to evolve gracefully, one independent service at a time.
Alright, let us pause and reflect. We've got our language straight—publishers, subscribers, and brokers are now part of our vocabulary. It's time to open up the architectural toolbox. Think of these event driven patterns less like rigid blueprints and more like battle tested recipes for solving specific problems in distributed systems.
Each pattern offers a unique way to handle data, state, and complex workflows. Picking the right one is a bit like choosing between a hammer and a screwdriver. They both fasten things, but you wouldn't use one for the other's job.
Event Sourcing: The Ultimate Audit Log
Ever wished you could rewind time to see exactly how your application's data ended up in its current messy state? That's the problem Event Sourcing solves.
Instead of just storing the current state of an object in your database (like a user's current address), you store a complete, append only log of every single thing that ever happened to it. The events themselves—UserRegistered, AddressUpdated, PasswordChanged—become the single source of truth.
Think of it like an accountant's ledger. You don't just see the final balance; you see every single credit and debit that led to it. To figure out the current state, you just replay the events in order. The beautiful side effect? You get a powerful, built in audit trail for free.
CQRS: Separating Reads From Writes
Next up is CQRS, which is short for Command Query Responsibility Segregation. It sounds like a mouthful, but the core idea is wonderfully simple: the way you write data (Commands) should be completely separate from the way you read it (Queries).
In most applications, you read data way more often than you write it. CQRS lets you build two different models: one that's highly optimized for handling commands like CreateOrder, and a totally separate model built for speedy queries like GetOrderHistoryForUser. This split can massively boost performance and scalability because you can scale your read and write sides independently.
The Saga Pattern: Taming Distributed Transactions
In a simple monolithic world, database transactions have your back. They ensure a series of operations either all succeed or all fail together. But what happens when those operations are spread across a bunch of independent services? That's where the Saga pattern rides in to save the day.
A saga is basically a sequence of local transactions. Each step updates a database in one service and then publishes an event to kick off the next one. If any step fails, the saga triggers compensating transactions to roll back the changes made by the previous steps. It's an absolute must for keeping data consistent across services without locking them into tight coupling. I've seen firsthand how a well designed saga brings order to what would otherwise be a chaotic workflow, helping to build a high availability architecture that actually works.
You can coordinate a saga in two main ways:
- Choreography: This is the decentralized, "trust based" approach. Each service publishes events that trigger actions in other services. It's like a flash mob—everyone knows their part and reacts to the person before them without a central director. It's very decoupled, but tracking down where something went wrong can be a real headache.
- Orchestration: This approach uses a central "conductor"—a dedicated service that explicitly tells each participating service what to do and when. It's like a symphony conductor directing each instrument section. This makes the overall workflow much easier to follow and monitor, but it also introduces a potential single point of failure if your orchestrator goes down.
As you dig into these patterns, especially for building scalable and resilient systems, it's worth exploring the benefits of serverless architecture, as serverless platforms often rely on these exact event driven principles.
Transactional Outbox: Never Lose a Message
One of the most nerve wracking moments in an event driven system is the risk of a failure right between saving data to your database and publishing the event. What if the database commit works, but the message broker is down? Now your system is in an inconsistent state.
The Transactional Outbox pattern solves this problem with a clever, simple trick. Instead of publishing an event directly, you write the event to a special "outbox" table within the same database transaction as your business data. A separate, reliable process then reads from this outbox table and publishes the events. This setup guarantees that an event is published if and only if the database transaction was successful. No more lost messages.
Now that we've covered the core patterns, let's put them side by side to make the decision making process a bit clearer.
Choosing Your Architectural Tool
Here's a comparative look at the primary event driven patterns, highlighting their ideal use cases, benefits, and potential complexities to help you make informed design decisions.
| Pattern | Best For | Key Benefit | Main Tradeoff |
|---|---|---|---|
| Event Sourcing | Systems requiring a full audit history or the ability to replay state over time. | Complete, immutable history of every change. The ultimate source of truth. | Can be complex to query the current state. Requires "replaying" events. |
| CQRS | Applications with different read/write patterns, like high traffic dashboards or complex reporting. | Independent scaling of read and write models, leading to better performance. | Increased architectural complexity; requires managing two data models. |
| Saga | Managing long running, multi step business processes across different microservices. | Ensures data consistency across services without tight coupling or distributed locks. | Debugging can be challenging, especially with the Choreography approach. |
| Transactional Outbox | Critical operations where you must guarantee an event is sent after a database update. | Guarantees "at least once" delivery and prevents data inconsistencies. | Adds a bit of latency and requires an extra background process to publish events. |
Each of these patterns is a powerful tool when used in the right context. The trick is to understand the problem you're solving first, then pick the tool that best fits the job, rather than forcing a single pattern onto every problem you encounter.
Building a Real World Example
Theory is fantastic, but let's be honest—nothing makes a concept click quite like seeing it in action. So, let's roll up our sleeves and move from abstract diagrams to tangible code. We're going to build a small but realistic example using a workhorse tech stack many of us know and love: Django, Celery, and RabbitMQ.
Our scenario is a classic e commerce workflow that happens thousands of times a day: a customer places a new order. In a monolithic setup, this single action could trigger a long, fragile chain of synchronous calls. But we're going to build it the event driven way. You can follow along.
Setting the Stage: The Order Process
Imagine a user just clicked "Complete Purchase." Our Django application needs to do several things, but not all of them have to happen right now for the user to get a success message.
Here's the game plan:
- The Publisher (Django): Our primary Django application will handle the initial request, create an
Orderobject, and save it to the database. Its final job is to publish a single, simple event:OrderCreated. - The Subscribers (Celery Workers): We'll set up multiple, independent Celery workers that are listening for that one event. Each worker has a different job to do, and they can all run in parallel.
This separation is the heart of our example. The Django web server's only responsibility is to confirm the order and announce it. It doesn't need to wait for emails to be sent or inventory to be updated. That decoupling is what gives us resilience and speed.
This diagram shows how our key event driven architecture patterns fit together, forming a powerful toolkit for building these kinds of systems.
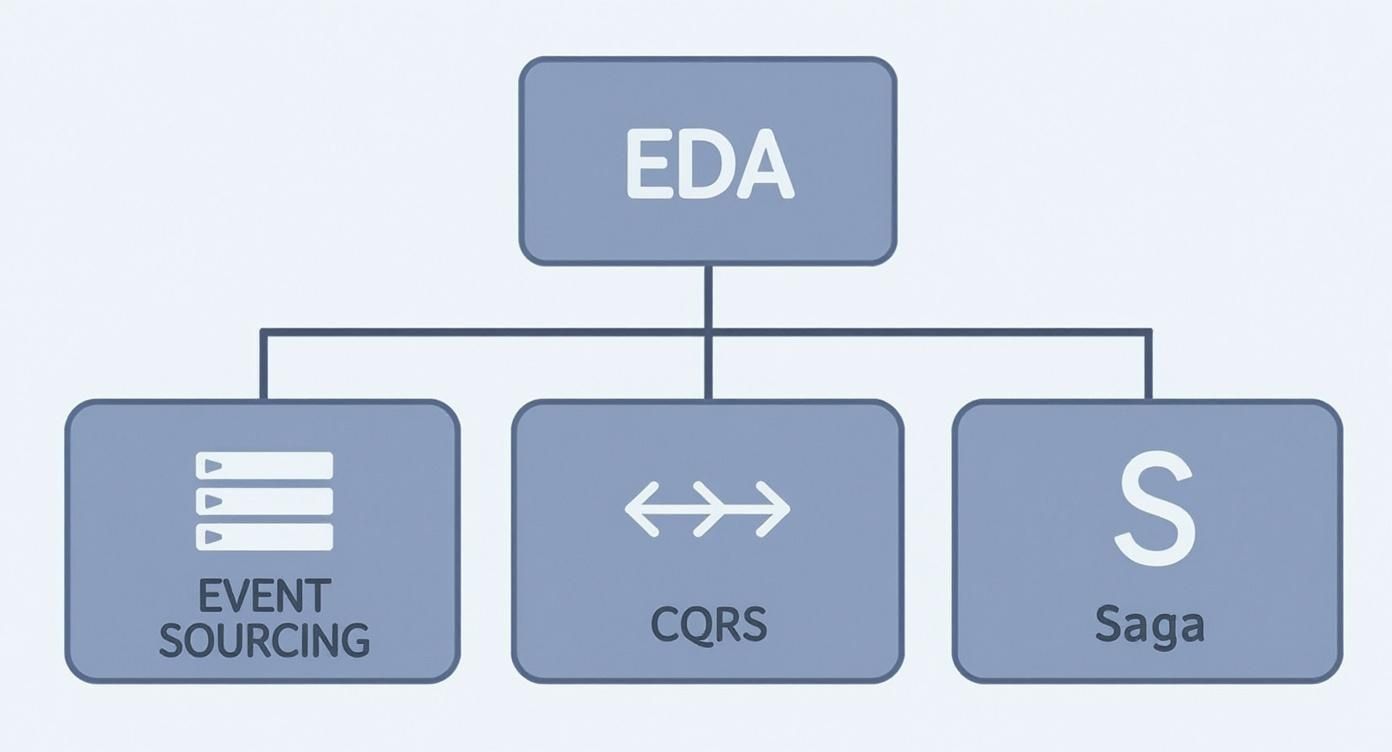
You can see how patterns like Event Sourcing, CQRS, and Saga are all implementations under the broader umbrella of Event Driven Architecture, each solving a specific problem in a decoupled system.
The Publisher Code: A Django View
Let's look at what the Django view might look like. After validating the incoming request and creating the order, the final step is simply to publish the event.
In your Django orders/views.py
from .tasks import process_order_event
from .models import Order
def create_order(request):
# ... logic to validate cart and create the order object ...
new_order = Order.objects.create(...)
# This is the magic moment! We publish the event.
# We're just sending the ID, not the whole object.
process_order_event.delay(order_id=new_order.id)
# Return a success response to the user immediately.
return JsonResponse({"status": "success", "order_id": new_order.id})
Notice how clean that is. We call process_order_event.delay(). This is Celery's way of saying, "Hey, put this task onto the RabbitMQ queue and return immediately." From the user's perspective, the web request is now finished.
The Subscriber Code: Celery Tasks
Now for the fun part. We can create multiple tasks that all trigger from that single event. Using a Celery group, we can fire off several independent tasks all at once.
In your Django orders/tasks.py
from celery import shared_task, group
from .services import (
update_inventory_service,
send_confirmation_email_service,
notify_shipping_department_service
)
@shared_task
def update_inventory(order_id):
# Logic to decrement stock for items in the order
update_inventory_service(order_id)
@shared_task
def send_confirmation_email(order_id):
# Logic to fetch order details and email the customer
send_confirmation_email_service(order_id)
@shared_task
def notify_shipping(order_id):
# Logic to create a shipping manifest or notify the warehouse
notify_shipping_department_service(order_id)
@shared_task
def process_order_event(order_id):
# This is our "fan out" task. It triggers all other tasks.
job = group(
update_inventory.s(order_id),
send_confirmation_email.s(order_id),
notify_shipping.s(order_id)
)
job.apply_async()
With this setup, updating inventory, sending an email, and notifying shipping are three completely separate, parallel processes. If the email service is slow, it has zero impact on the inventory update. That's the resilience we were talking about.
This example only scratches the surface, but it turns abstract concepts into a concrete implementation. For those looking to go deeper into this exact stack, my DjangoCon US 2024 tutorial on mastering asynchronous tasks with Celery, RabbitMQ, and Redis provides a much more detailed walkthrough. You can take this basic pattern and expand it to handle dozens of downstream services without ever modifying that initial create_order view.
So, you've built a shiny new event driven system. Everything is decoupled, scalable, and humming along nicely. But what happens when that hum turns into a mysterious buzz, and something, somewhere, goes wrong?
Moving to an event driven architecture isn't just a technical swap out; it's a complete operational shift. It comes with its own special brand of challenges that can be absolutely maddening if you aren't ready for them. This is the "lessons learned from the trenches" part of our guide. The promises of EDA are real, but so are the headaches of running it in production. Let's get into the tough stuff.
The Agony of Asynchronous Debugging
In a simple, synchronous world, debugging is pretty straightforward. You follow a stack trace, and you can see the entire journey of a request from start to finish. In an event driven system, that neat, linear path completely shatters.
A single click from a user might kick off a cascade of events that bounce between half a dozen services. When a customer calls in saying their order status is stuck, where do you even begin to look? The initial event might have published just fine, but did the inventory service ever pick it up? Did the shipping service time out while trying to process it?
This is where observability becomes your non negotiable best friend. Just logging messages to the console isn't going to cut it anymore. You need tools that can piece the fragmented story back together.
- Correlation IDs: This is the absolute baseline. You generate a unique ID at the very start of a workflow (say, when an order is created) and make sure it's passed along with every single event in that chain. When you need to investigate, you can search all your logs for that one ID and see the entire journey across every service. It's like a passport for your event.
- Distributed Tracing: Think of this as the supercharged version of correlation IDs. Tools like OpenTelemetry or Jaeger give you a visual "flame graph" of the entire event flow. You can instantly see which service took the longest, exactly where an error occurred, and how long messages sat rotting in a queue. It turns debugging from pure guesswork into a data driven hunt.
Testing in a World of Uncertainty
How do you write a reliable test for something that happens "eventually"? Your standard unit tests are still crucial for checking your business logic, but they won't catch a misconfigured broker or a mismatched message contract. This is where testing gets a lot more interesting.
Writing tests for asynchronous systems requires a mindset shift. You're no longer just testing inputs and outputs; you're testing conversations and agreements between services that might never directly speak to each other.
To build real confidence in your system, you need to layer your testing approach:
- Component Testing: Instead of just mocking your message broker, write tests that spin up a real (but lightweight) instance of RabbitMQ or Kafka in a Docker container. This way, you're testing your service's actual ability to publish and consume messages using the real wire protocol. It's brilliant for catching configuration errors long before they hit production.
- Contract Testing: What happens when the
OrderCreatedevent schema changes? One team adds a field, another removes one, and suddenly everything breaks in production. A contract testing tool like Pact can save you. It creates "contracts" that define the expected structure of an event, ensuring that your event publishers and subscribers stay in sync. If a publisher makes a breaking change, the contract test fails, preventing a catastrophic production outage.
And of course, ensuring the resilience and continuous availability of your entire system is paramount. This often requires robust strategies for your critical components, such as implementing Multi Provider Failover Reliability.
This whole ecosystem is what makes scaling these architectures possible. We're seeing huge advances in cloud native event brokers, developer platforms, and compliance tools that are making adoption easier. Managed services from cloud providers lower the barrier to entry, letting companies handle billions of events daily, while tools like Zapier are expanding event driven workflows beyond just engineering teams.
We've covered a lot of ground, from the basic language of events to the thorny realities of debugging asynchronous systems. It can feel like a lot to take in. Let's pause for a second and boil all that theory down into a practical cheat sheet for your next project.
Think of these as the core principles to keep in your back pocket when you're weighing which event driven patterns to bring into your stack.
Core Principles to Remember
- Start with a Problem, Not a Pattern: Seriously, before you even whisper the word "Kafka" or "Sagas," get crystal clear on the problem you're solving. Are you trying to make a critical workflow more resilient? Scale a specific, overloaded service? Decouple two teams so they can ship independently? The right pattern falls out of a well defined problem, not the other way around.
- Decoupling is Your North Star: The whole point of this is to let services evolve on their own terms. A publisher should have zero knowledge of who is listening. If you find yourself writing logic in a producer that depends on what a downstream consumer does, stop. You're coupling them, and you need to take a step back.
- Observability is Not an Afterthought: Don't even think about building an event driven system without a concrete plan for correlation IDs and distributed tracing. Debugging without them is a special kind of hell you want to avoid at all costs. I once burned half a day hunting for a "lost" event, only to find another service was accidentally consuming it because of a misconfigured topic. Never again.
The real power of event driven architecture comes from the operational freedom it gives your teams. Embrace asynchronicity, but don't disrespect the complexity it introduces. Your future self, debugging a production issue at 2 AM, will thank you for it.
Your Cheat Sheet for Starting Small
You don't need to re architect your entire application in one go. In fact, that's a fantastic recipe for disaster. The smart move is to find one small, non critical workflow and just experiment.
- Pick a safe candidate: A user notification system is perfect for this. So is a background job that crunches analytics data. These are great places to learn without breaking your core product.
- Use the tools you know: If your team already uses Celery and RabbitMQ, stick with them for now. The goal is to learn the patterns first, then you can go explore shiny new tech.
- Measure everything: You need to know how long events are sitting in queues and how much time consumers are taking to process them. This data is pure gold for tuning and troubleshooting later.
The numbers show that getting this right really pays off. Organizations that adopt EDA report a 47% improvement in system resilience and get new features to market 68% faster. When you're trying to connect a bunch of different systems, it can also slash integration complexity by as much as 73%. You can read the full research about these findings to see the data for yourself.
The journey into event driven architecture patterns is an iterative one. Start small, learn from your mistakes (you'll make some!), and build on your wins.
Frequently Asked Questions
A few common questions always pop up when developers first start poking around event driven architectures. Let's tackle them head on, because if you're wondering about it, someone else is too.
When Should I Not Use Event Driven Architecture?
As powerful as these patterns are, they are not a silver bullet. I once tried to build a simple CRUD application with a full blown event driven design, and the complexity was just ridiculous for what it did.
You should probably stick to a simpler, synchronous model when:
- You're building a simple CRUD app: If your application is mostly just creating, reading, updating, and deleting records with straightforward logic, the overhead of a message broker and asynchronous workflows is almost never worth it.
- Immediate, synchronous feedback is required: If a user performs an action and must get an immediate, guaranteed confirmation that a multi step process is complete, EDA can make this tricky. Think of a real time stock trade execution—it needs that instant, blocking confirmation.
- Your team is new to distributed systems: The operational and debugging challenges are real. It's far better to master a well structured synchronous system first than to dive into an event driven one without being prepared for the complexity.
How Do I Handle Event Versioning And Schema Changes?
This is a big one, and a source of many late night production fires if not handled carefully. You can't just change an event schema on a whim, because you might break dozens of downstream services you didn't even know were listening.
The key is to treat your events like a public API: changes should always be backward compatible.
Your goal is to allow older consumers to keep functioning even when a new version of an event is published. Never make a change that forces all your subscribers to deploy in lockstep with the publisher.
Here are a few battle tested strategies to keep things from blowing up:
- Always add, never remove: Favor adding new, optional fields over removing or renaming existing ones. Older consumers will simply ignore the new fields they don't understand.
- Use a schema registry: Tools like the Confluent Schema Registry enforce compatibility rules automatically. They can prevent a developer from accidentally deploying a breaking change to an event schema, acting as a crucial safety net.
What Is The Difference Between A Message Queue And An Event Stream?
This question causes a lot of confusion because technologies like RabbitMQ and Kafka are often mentioned in the same breath. While both move messages around, their core philosophies are very different.
A Message Queue (like RabbitMQ or AWS SQS) is typically about distributing work. A message is put on a queue, and one consumer pulls it off, processes it, and then the message is gone. It's like a to do list for your services.
An Event Stream (like Apache Kafka) is designed as a durable, replayable log of facts. Events are written to a topic and stay there. Multiple consumers can read the same stream of events independently, and you can even "replay" the entire history of events to rebuild a system's state. It's more like a historical ledger than a to do list.
Building robust, scalable systems is a journey of thoughtful architecture and deep execution. I help early stage startups accelerate their roadmaps with production grade Django applications, AI integrations, and secure, scalable backends. Let's build something great together.
Subscribe to our newsletter.
Become a subscriber receive the latest updates in your inbox.


Member discussion