

It always starts with that frantic 3 AM alert: 'The site is down.'
We have all been there. That sinking feeling as you scramble to figure out what just broke is a rite of passage for many of us in the industry. I still remember the cold sweat from my first major production outage; it felt like the entire internet was staring at me.
This guide is for every engineer who has stared at that error screen and vowed, "never again." We are not talking about abstract theory here; we are talking about practical, battle tested high availability architecture that keeps your services running, your users happy, and most importantly, lets you get a good night's sleep.

So, what is a high availability architecture? At its heart, it is simply a system designed to stay online and accessible almost all the time. It is built on core principles like redundancy (having backups for everything) and automatic failover (switching to a backup instantly when something breaks) to swallow hardware failures, software bugs, or network hiccups without your users ever noticing.
Why This Journey Matters
Our journey will take us from the fundamental ideas that prevent failure to seeing them applied in the real world. This is not just about server uptime; it is about building trust and reliability into the very fabric of your product. For many businesses, continuous operation is not just a feature, it is the entire business model.
High availability is absolutely critical in sectors where even a minute of downtime translates into massive operational and financial losses. Think about healthcare systems managing electronic health records, where availability needs to be near 99.999% to ensure patient data is always accessible. Or financial services, where every second of uptime is crucial for processing transactions. You can find more insights on high availability's impact at IBM.
This path is about making conscious choices. We will explore:
- The Painful Lessons: Learning from real world outages and near misses.
- The Necessary Trade Offs: Balancing cost, complexity, and the level of resilience you actually need.
- The Patterns That Work: From resilient Django applications to modern AI pipelines, we will look at architectures that hold up under pressure.
Let us pause and reflect. We are going to move beyond just "keeping the lights on." The goal is to build systems that can withstand the chaos of production environments, gracefully handle failures, and recover automatically, often without any human intervention. This is what truly robust engineering looks like.
Understanding the Principles of Resilient Systems
Before we get bogged down in complex architecture diagrams and code snippets, let us take a step back. Building a highly available system is not about picking a specific technology off a shelf; it is about adopting a certain mindset. It is a way of thinking built on a few powerful, almost common sense principles that, when combined, create systems that can actually weather a storm.
Think of it less like black magic and more like engineering a bridge. You do not just hope it stays up; you build in safety margins, backup supports, and ways for it to flex under stress without collapsing. Our systems are no different.
Redundancy: The 'Have a Spare' Rule
At its absolute core, high availability begins with redundancy. It is the simple, brilliant idea of having a backup for everything that is critical. I once lost an entire weekend rebuilding a server from scratch because a single, non redundant power supply failed in a spectacular plume of smoke. Never again.
This principle is everywhere you look in the real world. A plane has a pilot and a copilot. A hospital has backup generators. Your application needs the exact same kind of thinking:
- Spare Servers: If one server goes down, another identical one is ready to instantly take its place.
- Duplicate Databases: A primary database might handle all the writes, but one or more replicas are always in sync, just waiting to be promoted.
- Multiple Network Paths: You have to ensure there is not one single cable or network switch whose failure can sever communication to a critical component.
Redundancy is your first and most important line of defense against the inevitable, something, somewhere, is going to fail. It is not a matter of if, but when.
Automatic Failover: The Invisible Switch
Having a backup is completely useless if you have to wake up at 3 AM to manually switch over to it. That is where automatic failover comes in. It is the brain of a resilient system, the mechanism that detects a failure and seamlessly redirects traffic to the redundant component without any human intervention.
This switch needs to be fast and flawless. A slow failover is just a slightly delayed outage from the user's perspective. The goal is for your user to experience a momentary blip at worst, or ideally, nothing at all. This is the difference between a minor incident report and a full blown crisis call.
Partitioning: The Bulkhead Strategy
Imagine an old ship with a single, open hull. If it springs just one leak, the entire ship floods and sinks. Shipbuilders solved this centuries ago by adding bulkheads, watertight compartments that isolate a breach. If one section floods, the others remain dry, and the ship stays afloat.
Partitioning, sometimes called bulkheading, applies this exact concept to software architecture. The goal is to isolate components so that a failure in one area does not cascade and take down the entire system. A catastrophic bug in the user profile service should never be able to crash the payment processing service. This is a core idea behind microservices, but the principle applies even in monolithic systems. By creating clear boundaries and preventing dependencies from becoming a tangled mess, you contain the blast radius of any single failure.
Graceful Degradation: Failing Softly
Look, sometimes a full outage is unavoidable in a specific part of your application. The key is to fail softly instead of crashing hard. Graceful degradation is the art of maintaining partial, essential functionality even when some components are broken.
For example, if your machine learning powered recommendation engine goes down, maybe you hide that section of the webpage or just show a generic list of "popular items" instead. The user can still browse, add items to their cart, and check out, even though one fancy feature is temporarily offline. This is infinitely better than showing them a generic "500 Internal Server Error" page.
This strategy fits into a wider operational picture. For a broader perspective on maintaining operations during disruptions, consider the importance of robust business continuity policies, which outline how an entire organization can respond to and recover from incidents. These four principles, redundancy, failover, partitioning, and graceful degradation, are the bedrock of any serious high availability architecture.
Diving Into High Availability Architecture Patterns
Alright, now we get to the good stuff, where theory hits the pavement. Moving from principles to actual architecture patterns is like learning musical scales and then finally writing a song. The principles are your foundation, but the patterns are how you creatively arrange them to build a system that can take a punch.
Let us walk through some of the most common high availability patterns and, more importantly, the real world trade offs you will face with each one.
This diagram shows how those core ideas we talked about, redundancy, failover, and partitioning, all click together to create a resilient system.
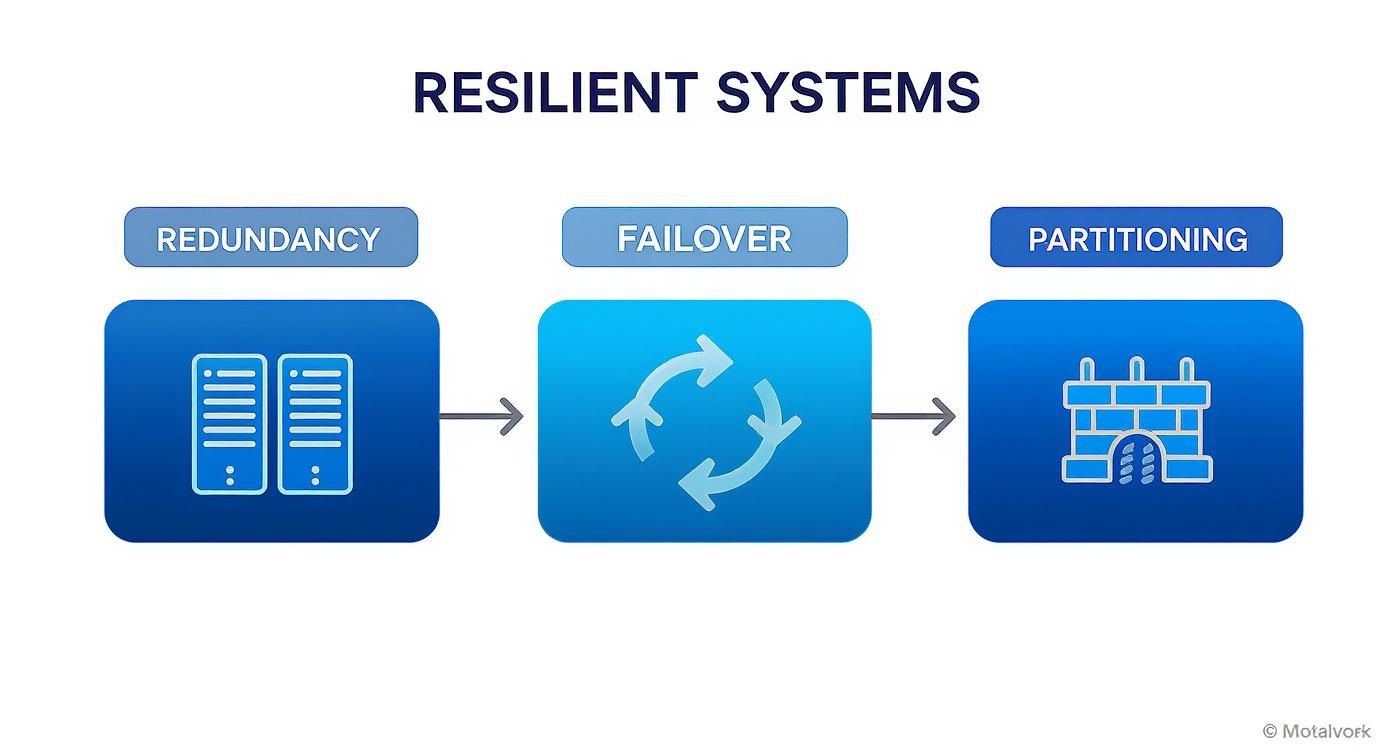
See how each piece builds on the others? A truly tough system is not about a single magic bullet; it is about layering your defenses against failure.
Active Passive: The Standby Companion
The most straightforward way to introduce redundancy is the Active Passive setup. Think of it like this: you have two identical web servers. One server, the "active" one, is on the front lines, handling all the user traffic. The second server, the "passive" one, is fully configured and ready to go, but it is just sitting on the sidelines, waiting for its big moment.
A monitoring system, often called a "heartbeat," keeps a constant eye on the active server. If it detects a failure, poof, the server is gone, a failover process kicks in. This process automatically reroutes all incoming traffic to the standby server, which instantly becomes the new active instance. It is a classic for a reason.
- Pros: It is relatively simple to set up and manage. The cost is somewhat lower since your standby resources are idle (though they really should be identical to production).
- Cons: That passive server is essentially "wasted" resources until a failover is needed. Plus, the failover process itself is not instantaneous. It can take a few seconds to a minute, causing a brief service blip for your users.
This pattern is a fantastic starting point for many applications that can handle a very short window of downtime during that switch.
Active Active: The "All Hands on Deck" Approach
Ready to kick things up a notch? Let us talk about an Active Active architecture. In this setup, you have two or more servers, and all of them are handling user traffic at the same time. A load balancer sits out front, intelligently spraying requests across all the active instances.
If one server goes down, the load balancer just shrugs and stops sending traffic its way. The remaining servers simply pick up the slack. There is no dramatic "failover event" because the system was already running in a distributed state.
This pattern offers a massive advantage: zero downtime for a single server failure. From a user's point of view, the service might get a tad slower as the other servers handle more load, but it never goes dark.
Of course, this elegance does not come free. Active Active systems are trickier to design. You have to build your application to be stateless or ensure that state is managed in a shared, external system (like a database or cache) so that any server can handle any user's request.
Comparing High Availability Patterns
Choosing the right pattern can feel overwhelming. This table breaks down the common approaches, their trade offs, and where they shine, helping you match the right strategy to your system's needs.
| Pattern | Core Idea | Pros | Cons | Best For |
|---|---|---|---|---|
| Active Passive | A primary server handles traffic; a standby server is idle and ready to take over. | Simple to implement, lower operational complexity. | "Wasted" resources on the passive node, brief downtime during failover. | Applications that can tolerate a few seconds of downtime and want a straightforward setup. |
| Active Active | All servers handle traffic simultaneously, managed by a load balancer. | Zero downtime for single node failures, efficient resource usage. | More complex to design, requires stateless applications or external state management. | Critical services that demand zero downtime deployments and can handle the complexity. |
| Multi Region | The entire infrastructure is duplicated in a separate geographical region. | Ultimate protection against large scale regional outages (e.g., data center failure). | Highest cost and complexity, requires robust data replication strategies. | Mission critical global services where regional resilience is non negotiable. |
| Database Replication | A primary database handles writes, which are copied to one or more read replicas. | Improves read performance and provides a hot standby for the primary database. | Failover can be complex; replication lag can cause stale data on replicas. | Most applications that need both database resilience and scalable read capacity. |
Each pattern offers a different balance of resilience, cost, and complexity. The key is to understand what your application truly needs and not over engineer (or under engineer) your solution.
Expanding to Multi Region Setups
What happens when an entire data center or cloud region goes offline? This is not just a hypothetical scenario, it happens. Cloud providers experience regional outages from network failures, power cuts, and even natural disasters. For mission critical services, a multi region architecture is the only real answer.
In a multi region setup, you replicate your entire stack across two or more geographically separate locations. You might have your primary deployment running in US East, with a complete, synchronized replica humming along in US West.
If the US East region goes down, you can redirect all global traffic to the US West deployment. This is your ultimate insurance policy against large scale disasters. If you want to go deeper, there are excellent resources on designing for High Availability and Disaster Recovery that cover various approaches.
Keeping Your Data Layer Resilient
Your application servers are just one piece of the puzzle. The stateful parts, your databases, caches, and message queues, are often the trickiest to make highly available.
- Database Replication: A common setup is the primary replica model. The primary database handles all the write operations, which are then streamed to one or more read replicas. If the primary database fails, you can promote a replica to become the new primary, ensuring your data is safe.
- Resilient Caching: Tools like Redis can be configured in a cluster with automatic failover. If one Redis node dies, another takes its place. This is crucial for preventing a cache failure from causing a "thundering herd" problem where your database gets overwhelmed.
- Robust Message Queues: Systems like RabbitMQ can also be clustered. If one node fails, your asynchronous tasks are not lost, and the queue keeps chugging along. These queues are fantastic shock absorbers in a distributed system.
These patterns rarely exist in isolation. Many of these concepts are especially critical when you start building with a distributed design; you can learn more in our guide on microservices architecture best practices. True resilience comes from thoughtfully combining these server, data, and component level patterns into a cohesive whole.
Building a Resilient Django Application
Theory is great, but let us get our hands dirty. We are going to walk through the journey of taking a typical Django application from a fragile, single server setup to a robust, high availability architecture. I still remember the anxiety of my first solo deployment; a single virtual machine holding the app, the database, and all my hopes and dreams. Every git push was a prayer.
We are going to build something much, much better.
The goal here is not to flip a single switch. It is about adding layers of resilience, one step at a time, progressively hardening your system. We will start with a common, and vulnerable, deployment and see how each new piece of the puzzle reduces risk and improves uptime.
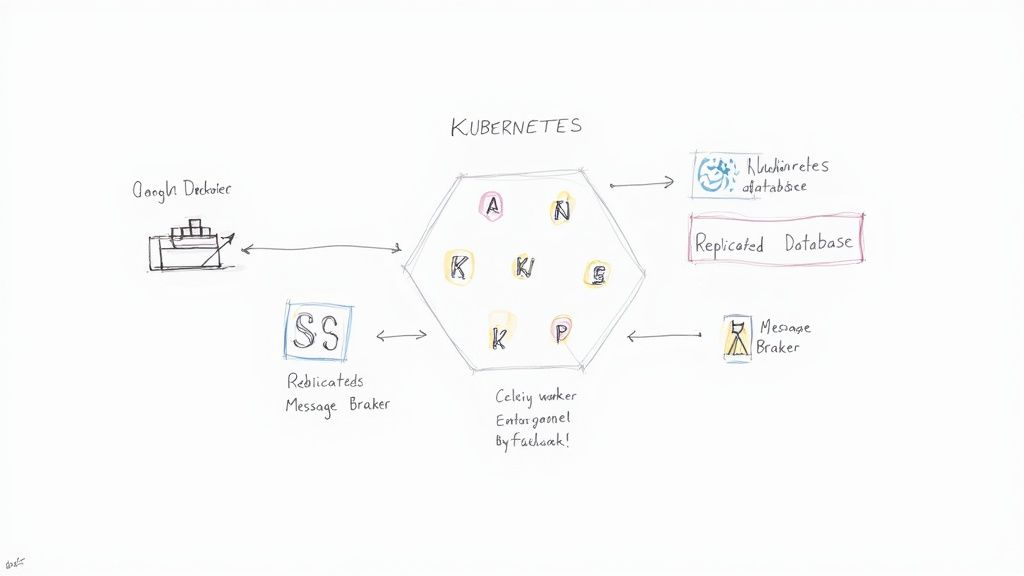
This diagram shows where we are headed: a system with multiple application instances, a resilient database, and a robust message broker, all working in concert.
From Single Server to Containerized Fleet
Our starting point is the classic single server deployment. One machine runs our Django app via Gunicorn, Nginx as a reverse proxy, and a PostgreSQL database. It is simple, but it is a house of cards. If that server goes down for any reason, hardware failure, a bad deploy, a network hiccup, the entire application is gone. This is the definition of a single point of failure.
Our first move is containerization with Docker. By packaging our Django application into a Docker image, we create a consistent, portable unit. It runs the same on my laptop as it does in production, which stamps out those frustrating "but it works on my machine" bugs for good.
Once containerized, we bring in an orchestrator like Kubernetes. This is the real game changer. Instead of one server, we can now run multiple identical copies (called pods) of our Django application.
- Self Healing: If a container crashes, Kubernetes automatically restarts it. No 3 AM alerts needed.
- Redundancy: We can run, say, three replicas of our application. If one pod goes down, the other two keep serving traffic without missing a beat.
- Scalability: If traffic spikes, we can tell Kubernetes to scale up to ten pods with a single command. When things quiet down, we can scale back down just as easily.
Kubernetes handles the automatic failover for our application layer, effectively giving us an active active setup for our stateless Django app.
Tackling the Stateful Beast: The Database
Okay, our Django app instances are now redundant, but they all still point to that one PostgreSQL database. If the database goes down, our highly available app fleet is completely useless. The database is our new single point of failure.
Moving from a single instance to a managed, replicated setup is a critical step. Services like Amazon RDS or Google Cloud SQL make this much easier than it used to be. We can configure a primary replica architecture.
All write operations go to the primary database. That data is then automatically replicated to one or more standby replicas. If the primary database fails, the managed service can automatically promote a replica to become the new primary, usually with only a minute or two of downtime for the switch.
This setup not only provides failover capabilities but also lets us direct read heavy queries to the replicas. This reduces the load on our primary database and boosts overall performance. Designing APIs that handle these database states correctly is crucial, and you can explore more on how to build fail safe APIs in Django in our related guide.
Ensuring Asynchronous Tasks Never Die
Many Django applications rely on Celery for background tasks, using RabbitMQ as a message broker and Redis for storing results. This introduces even more potential points of failure. What happens if the RabbitMQ server crashes? All our asynchronous tasks get dropped on the floor.
To make this part of our architecture resilient, we need to address both the broker and the workers.
- Highly Available Message Broker: RabbitMQ can be configured in a clustered mode. With a cluster, messages are replicated across multiple nodes. If one node goes down, the queue remains available, and no tasks are lost.
- Redundant Celery Workers: Just like our Django app, we run multiple Celery worker containers managed by Kubernetes. If one worker pod crashes mid task, another worker can pick it up (with the right task configuration, of course).
This combination ensures that our background processing system is just as robust as our user facing web application.
Resilience in the Age of GenAI
Modern applications, especially those leveraging GenAI and Retrieval Augmented Generation (RAG), introduce a whole new set of components that need protection. Let us say our Django app calls out to a separate service for model inference or queries a vector database like Pinecone or Weaviate.
- Model Serving Failures: The service running your LLM needs to be highly available. This often means deploying the model on multiple instances behind a load balancer, just like our Django app. If one model server fails, traffic is seamlessly routed to a healthy one.
- Vector Database Availability: Most production grade vector databases are managed services that offer high availability configurations. You have to make sure you have enabled these features so a single node failure in the vector database cluster does not bring down your RAG functionality.
- Graceful Degradation: If an AI service does fail, the main application should handle it gracefully. Instead of crashing, perhaps the feature that relies on the AI is temporarily disabled with a clear message shown to the user.
Building a truly resilient high availability architecture is an iterative process of identifying and eliminating single points of failure, layer by layer. We have moved from a fragile single server to a distributed system where the failure of any one component does not cause a total outage.
Proving It: Monitoring and Chaos Engineering
Building a resilient system is a fantastic first step. But how do you know it actually works?
I once spent a week crafting what I thought was a beautifully redundant architecture, only to discover during a minor network blip that my failover logic had a subtle, fatal bug. It was a humbling moment, to say the least. This section is all about moving from hoping your system is resilient to proving it with hard evidence.
It all starts with defining what "available" even means for your specific application. Just aiming for high uptime is not enough; you need a concrete target. This is where Service Level Objectives (SLOs) come into play.
An SLO is a specific, measurable target for your system's reliability. For example, you might set an SLO that 99.9% of login requests over a 30 day period must succeed in under 500ms.
This simple number changes everything. It becomes your team's north star, guiding every decision from shipping new features to planning infrastructure upgrades. Without an SLO, you are just flying blind.
Embracing Controlled Chaos
Once you have your targets, it is time to get proactive. This is where we step into the world of Chaos Engineering.
The idea is simple but incredibly powerful: instead of waiting for things to break, you intentionally break them yourself in a controlled environment. It sounds terrifying, I know, but it is the single best way to uncover hidden weaknesses before your users do.
A classic tool for this is Chaos Monkey, originally developed by Netflix. It works by randomly terminating virtual machine instances and containers right in your production environment. If your system is truly resilient, it should handle this loss without any user visible impact. The first time you run it is a nerve wracking experience, but the confidence it builds is immeasurable.
This proactive approach is critical, especially when you consider the explosive growth in infrastructure demand. Data center capacity in North America, a key pillar of any HA architecture, surged to 8,155 megawatts (MW) in early 2025, a stunning 43.4% year over year increase. Despite this massive build out, vacancy rates dropped to a historic low of 1.6%, driven by the relentless demand from cloud providers and AI companies that depend on this kind of resilient foundation. You can read more about this explosive data center growth at CBRE.com.
A Real World Chaos Story
On one project, we ran a chaos test that simulated a database replica falling significantly behind its primary. Our monitoring dashboards showed everything as "green," but we had a hidden flaw. A bug deep inside our database connection library meant that during a failover, our application would keep trying to read stale data from the old, out of sync replica for several agonizing minutes.
This would have caused a massive data integrity disaster during a real outage. The chaos test revealed a critical bug that our unit and integration tests had completely missed.
That experience solidified my belief that high availability is not a one time setup; it is a continuous practice of monitoring, testing, and hardening. This mindset shares a lot of DNA with a development discipline I am passionate about. If you are interested in building quality in from the ground up, you might find our guide on what is test driven development useful.
The Hidden Costs and Necessary Trade Offs
Let us be completely honest with each other for a moment: perfect availability is a myth. Chasing that mythical 100% uptime can be an incredibly expensive journey, often leading to over engineered systems that are a nightmare to maintain.
The real art of high availability architecture is not about blindly adding more servers; it is about making smart, pragmatic trade offs. We need to have a serious conversation about the "nines" of availability. Does a pre launch startup really need 99.999% uptime? Almost certainly not. The engineering effort, complexity, and sheer cost explode with each "nine" you try to tack on.
Understanding the Nines
The difference between these percentages might seem tiny on paper, but the reality in terms of downtime is huge. Let us break down what these numbers actually mean for your users.
- 99% (Two Nines): This means you can expect about 3.65 days of downtime per year. This is often perfectly fine for internal tools or services that are not customer facing.
- 99.9% (Three Nines): Now we are talking about roughly 8.77 hours of downtime annually. This is a common and respectable target for many growing applications.
- 99.99% (Four Nines): This shrinks the downtime window to just 52.6 minutes per year. Hitting this number requires a serious, intentional investment in redundant infrastructure and failover systems.
The so called "gold standard" is 99.999% uptime, or 'five nines,' which works out to a mere 5.26 minutes of downtime per year. Getting there means hunting down and eliminating every conceivable single point of failure, a monumental, and monumentally expensive, task. As you can read in this TechTarget.com overview of high availability, achieving this level of uptime is a massive undertaking.
Your goal should not be perfection; it should be building a system that is "available enough" for your specific users and business needs. Over engineering for uptime you do not need just burns cash and slows down your development. This is exactly the kind of architectural decision that gets scrutinized during fundraising, which is why we included it in our technical due diligence checklist.
A Few Lingering Questions
We have covered a lot of ground, from high level principles to specific architectural patterns. But a few common questions always pop up when engineers first start digging into high availability. Let us tackle them head on.
What is The Difference Between High Availability and Disaster Recovery?
This one trips a lot of people up, but the distinction is pretty simple.
Think of high availability (HA) as your system's ability to automatically survive small, common failures. A server crashing, a process dying, a network card giving up the ghost, these are HA problems. You solve them with things like redundancy and automatic failover, and ideally, your users never even notice a blip.
Disaster recovery (DR), on the other hand, is about surviving a full blown catastrophe. We are talking about an entire data center getting knocked offline by a flood or a massive power outage. That is a DR problem. Your solution here is not automatic; it is a procedural playbook for bringing your entire system back online in a completely different geographical region.
In short: HA prevents short interruptions, while DR gets you back in business after a major event.
How Much Is This Going To Cost My Startup?
Honestly, it varies wildly. There is no single price tag. A basic active passive setup for a web application might only bump your hosting bill by 20-30%. But if you are aiming for a full multi region, active active deployment with globally replicated databases, you could easily double or triple your infrastructure costs.
The key is not to boil the ocean on day one. Do not chase five nines of uptime when you are still chasing your first hundred customers. Start small. Implement redundancy for the most critical component first, that is almost always your database, and let your HA architecture grow alongside your revenue and user expectations.
Can I Get High Availability Without Using Kubernetes?
Absolutely. Kubernetes is an incredibly powerful tool for orchestrating containers, but it is far from the only game in town. High availability is a set of principles, not a specific technology.
You can build a rock solid, highly available system the old fashioned way. A load balancer distributing traffic across a handful of virtual machines running your application is a classic, and still highly effective, pattern.
Plus, managed services like AWS Elastic Beanstalk or Heroku bake a lot of these HA features in right out of the box. What matters most are the principles of redundancy and failover, not the specific tool you use to implement them.
What Are The Very First Steps I Should Take To Improve My App?
Start by hunting down your single points of failure (SPOFs). Ask yourself: "If this one component dies, does my entire system go down with it?" If the answer is yes, you have found your starting point.
For most early stage applications, the path looks something like this:
- Isolate Your Database: The very first thing to do is move your database off your application server. Get it onto a dedicated, managed service.
- Add a Load Balancer: Stick a load balancer in front of your application and run at least two application servers behind it.
- Use a Managed Database with Failover: Flip the switch on the automatic failover option in your managed database service. It is usually just a checkbox, and it is a lifesaver.
Nailing just these three steps will dramatically improve your application's resilience and put you on the right path.
Building a truly resilient, highly available architecture requires deep expertise in both systems design and your specific application stack. If you are an early stage startup looking to strengthen your technical foundation without slowing down your roadmap, Kuldeep Pisda offers consulting to design and implement robust, scalable systems that just work.
Subscribe to our newsletter.
Become a subscriber receive the latest updates in your inbox.


Member discussion