


Have you ever asked a chatbot a simple question and gotten a beautifully confident, yet completely wrong answer? I've been there. A while back, my team was building an internal tool to help our developers navigate our ever changing API documentation. The base Large Language Model was a wizard at explaining general coding concepts. But when we asked about a specific, recently updated endpoint, it hallucinated parameters that just didn't exist.
For our devs, this wasn't just a small bug. It was a trust killer. That frustrating experience put a spotlight on the core problem with even the most brilliant AI: its knowledge has an expiration date.

This is the journey we're about to go on. We'll start with that feeling of "why is my smart AI so dumb about my data?", explore the options, and land on the elegant solution that is Retrieval Augmented Generation, or RAG.
The Problem With Brilliant But Clueless AI
That experience with our internal tool taught me a valuable lesson. An LLM is like a brilliant student who studied for a final exam but showed up with last year's textbook. It's articulate, intelligent, but hopelessly out of date.
LLMs are trained on a massive but fixed snapshot of the internet. They have no idea what happened yesterday, no knowledge of your company's private data, and no clue about the latest commit to your codebase. Their world is frozen in time.
The Core Disconnect
This creates a fundamental gap. We expect our AI to be a helpful expert, but its pre trained knowledge often falls short in the real world where data is alive and constantly changing.
Without a way to access current, domain specific information, even the most advanced AI can't be trusted with mission critical tasks.
To truly grasp why this is such a big deal, you need to understand the inherent limitations of relying solely on LLMs. If you want to dig deeper, exploring the risks and limitations of using LLMs in business intelligence is a great starting point. It highlights why grounding these models in verifiable facts is an absolute must.
Bridging the Knowledge Gap
We needed to connect our eloquent AI to a source of truth. We had to transform it from a creative storyteller into a reliable expert. This is precisely the problem that Retrieval Augmented Generation was designed to solve.
Instead of just relying on its pre trained memory, RAG gives an LLM a superpower: the ability to look things up in real time. It connects the model to timely, verifiable information before it generates an answer. This simple but powerful upgrade is the key to building AI applications that are not just intelligent, but also accurate and trustworthy.
Let's pause here for a moment. What we've established is that standard LLMs have a knowledge gap. RAG is the bridge. Now, let's walk across that bridge and see how it's built.
So What is Retrieval Augmented Generation Anyway?
Let's ditch the jargon and try an analogy.
Imagine a brilliant history professor who, despite knowing everything up to the year they graduated, hasn't picked up a new history book since. They can write beautiful essays on ancient Rome, but ask them about anything recent, and they're completely lost. That's your standard Large Language Model.
Now, imagine giving that same professor a hyper efficient research assistant. Before answering any question, this assistant sprints to a massive, constantly updated library, finds the most relevant articles, and hands the professor a tidy summary. The professor then uses these fresh notes to craft a brilliant, current, and factually sound answer.
That's RAG in a nutshell. It's not a single thing but a powerful duo—the professor and the assistant—working in perfect harmony.
The Two Core Components
The entire RAG system really just boils down to two key players: the Retriever and the Generator. In our analogy, that's the research assistant and the professor.
- The Retriever (The Research Assistant): This component's entire job is to find the right information, fast. When you ask a question, the retriever doesn't just scan for keywords. It uses a clever technique called vector embeddings to grasp the actual meaning and intent behind your words. It then dives into a specialized database—your knowledge base—to pull out the most contextually relevant snippets of information. It's way smarter and faster than just hitting Ctrl+F on a bunch of documents.
- The Generator (The Professor): This is the LLM you're probably familiar with, like a GPT model. Its superpower is understanding language and generating text that sounds human. But here's the key difference: instead of relying only on its old, static training data, it gets a crucial briefing from the retriever. This new, relevant context is bundled up with your original prompt, giving the generator everything it needs to know.
This combination is a game changer. The Generator can now put together an answer that is not only well written but is also anchored in specific, verifiable facts pulled directly from your own data.
At its heart, RAG is about giving LLMs an open book test instead of a closed book one. It connects a powerful brain to a real time, curated library.
This concept isn't just a clever hack; it's a major shift in how we work with language models. The idea of Retrieval Augmented Generation was formally introduced by researchers back in 2020 who recognized the limitations of static AI models. The approach fundamentally changed how developers build with AI.
One of the biggest wins with RAG is how it boosts an AI's accuracy, essentially teaching it how to ground its responses in facts, a lot like the methods for using AI to answer questions like an expert. This often involves fetching data through a web service, a process you can learn more about in our guide on what is a REST API.
A Step By Step Guide to the RAG Workflow
Alright, we've talked about the professor and the research assistant. Now, let's get our hands dirty and trace the exact journey of a single question as it travels through a Retrieval Augmented Generation system. Seeing the moving parts in action is where the concept really clicks.
Let's say you're building a customer support chatbot. A user types in a pretty standard question: "What is the warranty period for the ProWidget X and does it cover accidental damage?"
Without RAG, a generic LLM would have to guess based on its vast but general knowledge of warranties. It might give a plausible but ultimately incorrect answer. With RAG, the system follows a precise, multi step process to give an answer grounded in your data.
Step 1: The Query and Initial Retrieval
First up, the system grabs the user's question and hands it off to the Retriever. The Retriever's only job is to scour its dedicated knowledge base—in this case, all your product manuals, policy documents, and internal FAQs—to find the most relevant information.
Crucially, it isn't just looking for the keyword "warranty." Modern systems use dense vector based search to understand the semantic meaning behind the query.
The tech here has come a long way. Early systems were stuck with basic keyword matching, but today's RAG models can filter documents with over 90% relevance accuracy. This is a huge deal, as it ensures only the most useful data gets passed along to shape the final answer. You can actually learn more about the evolution of RAG in generative AI to see how these techniques have developed over time.
Step 2: Augmentation and Prompt Engineering
Once the Retriever finds the top few relevant documents—let's imagine it pulls up the official ProWidget X warranty PDF and a couple of internal support articles—it doesn't just dump them on the next component. This is the "Augmented" part of RAG.
The system intelligently extracts the key text snippets from these sources and stitches them together with the user's original question. This creates a brand new, super charged prompt for the LLM that looks something like this:
Original Question: "What is the warranty period for the ProWidget X and does it cover accidental damage?"
Retrieved Context: "The ProWidget X comes with a two year limited warranty covering manufacturing defects. This warranty does not cover accidental damage, such as drops or water spills. An extended protection plan covering accidental damage is available for separate purchase."
New Prompt for the LLM: "Using the following context, answer the user's question: [Retrieved Context] + [Original Question]"
This new prompt basically gives the LLM an open book test. It has everything it needs to succeed.
Step 3: Generation of the Final Answer
Finally, this beefed up prompt is sent to the Generator (the LLM). Now, instead of hallucinating or guessing, the LLM's task is refreshingly simple: synthesize the information it was just given into a clear, human readable answer.
It will generate a response like: "The ProWidget X has a two year warranty that covers manufacturing defects. However, it does not cover accidental damage." The answer is accurate, directly sourced from your own documents, and completely trustworthy.
For more complex systems, you might even structure this data access through a dedicated backend. If you're curious about that side of things, you can explore our guide on how to make REST APIs in Django to learn more about the process.
This infographic does a great job of visualizing the entire RAG process, from digging through documents to generating that final, concise answer.
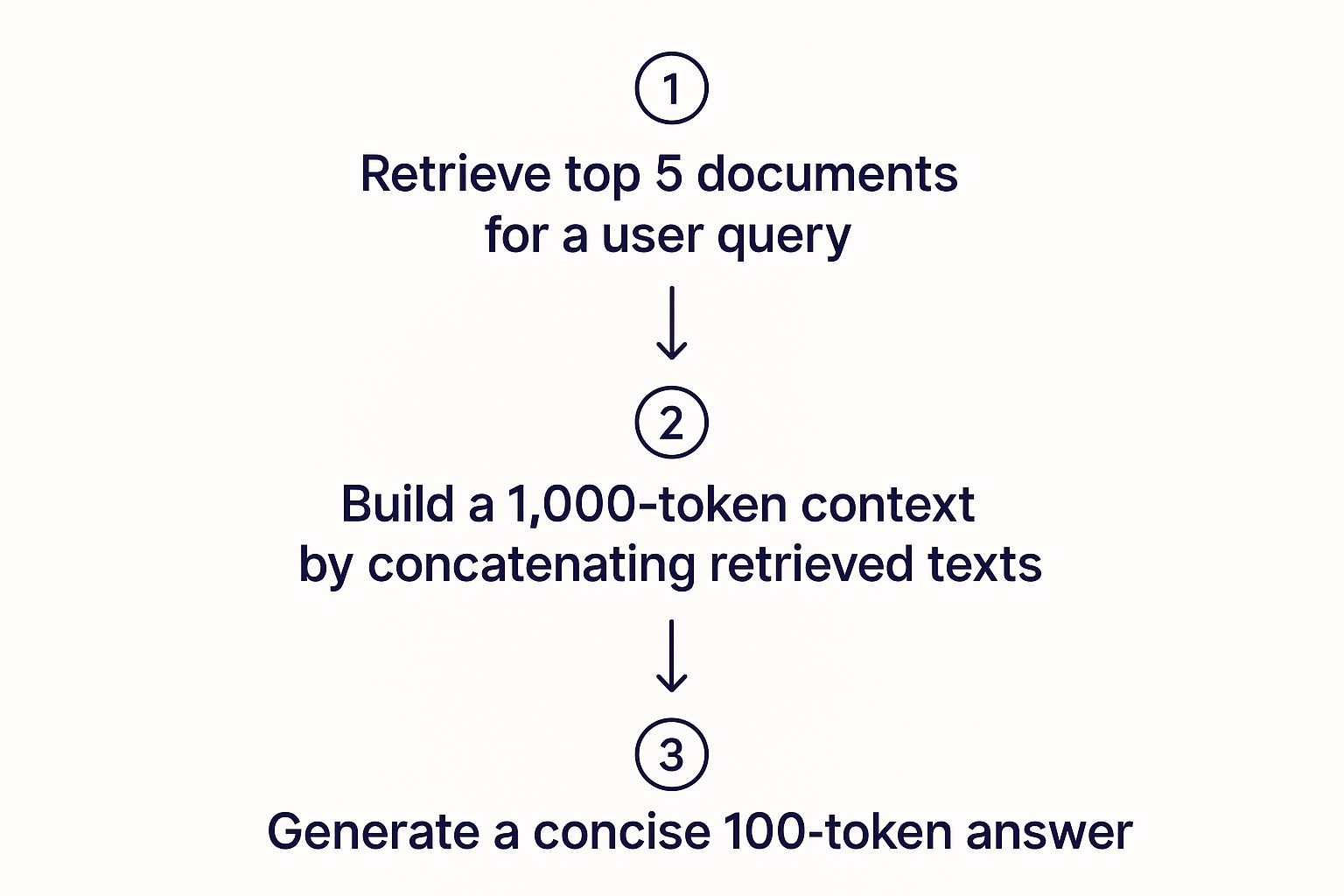
As you can see, the whole flow is about taking a large volume of potentially relevant text and distilling it into a highly focused and compact response.
The Real World Payoff of Using RAG
Theory is fantastic, but what really matters are the results that keep the lights on. Let's move past the diagrams and talk about the tangible, real world advantages you get when you actually implement Retrieval Augmented Generation.
What does RAG do for your application, your users, and your bottom line?
The first, and most celebrated, benefit is a dramatic drop in AI hallucinations. By grounding the LLM in verifiable, external data, you build far more trustworthy applications. You essentially turn your AI from a creative writer into a reliable expert.
Say Goodbye to Hallucinations
I once worked on a customer support bot that was notorious for giving frustratingly wrong answers. It would confidently invent return policies and product features out of thin air, causing absolute chaos for our human support team who had to clean up the mess.
The moment we implemented a RAG system that connected the bot to our actual policy documents and knowledge base, the transformation was immediate.
The bot went from a liability to an asset, providing accurate, source cited information that customers could trust. This is the primary impact of RAG—it forces the model to base its answers on facts, not just the statistical patterns it learned during training.
Keep Your AI Fresh and Efficient Without Costly Retraining
Another huge win is efficiency. Traditionally, if you wanted to update an AI's knowledge, you were looking at a costly and time consuming full model retraining. RAG completely sidesteps this process.
It's like giving your brilliant professor a new library card instead of sending them back to school for another four years. You simply update the knowledge base, and the model instantly has access to the new information.
This makes keeping your AI current incredibly agile. You can add new product docs, update company policies, or feed it real time news without ever touching the underlying LLM. This modular approach is a massive advantage, especially for systems that need to stay current.
The setup for these kinds of dynamic systems often involves careful orchestration of different services, a principle you can see in action in our Docker setup guide for beginners.
Build User Trust Through Transparency
Finally, RAG brings some much needed transparency to the AI black box. Because the system can point directly to the documents it used to formulate an answer, you're never left guessing where the information came from.
This has two key benefits:
- For Users: Citing sources builds immense trust. When a user sees that an answer is based on "Page 4 of the official user manual," they're far more likely to believe it and feel confident in the response.
- For Developers: This transparency is an absolute lifesaver for debugging. If the AI gives a strange answer, you can immediately check the retrieved context to see if the problem was with the retriever, the source data, or the generator. No more guesswork.
Before we go deeper, let's look at the pitfalls. Because trust me, there are plenty.
Look, no technology is a silver bullet, and Retrieval Augmented Generation has its own unique set of headaches. If you dive in thinking it's just a plug and play upgrade, you're setting yourself up for a world of frustration. It's critical to go in with your eyes open and have an honest look at the complexities you're about to take on.
The biggest issue, by far, is the timeless principle of "garbage in, garbage out." Your RAG system is only as good as the knowledge base it pulls from. If your source documents are riddled with errors, are hopelessly out of date, or just poorly organized, your AI will confidently serve up nonsense. The system itself can't magically fact check or clean up flawed source material.
When the Retriever Gets It Wrong
Another classic headache is a faulty retriever. Think of the retriever as your research assistant. What happens when that assistant runs off and grabs the wrong stack of books? You get a mess.
This can happen for a few reasons—maybe the user's query was a bit vague, or the vector search just wasn't tuned correctly. When the retriever fetches irrelevant junk, it hands that confusing context over to the LLM. The result? Answers that are completely off topic or just plain weird.
I once burned an entire afternoon debugging a RAG pipeline that was giving wildly incorrect financial data. It turned out to be a simple misconfiguration in the vector database embeddings. It was a humbling reminder: your retrieval component needs just as much love and attention as your generative model. A brilliant LLM can't save a botched retrieval process.
RAG vs Standard LLMs The Honest Tradeoffs
Choosing to build a RAG system means you're signing up for a whole new layer of complexity. It's a lot more involved than just hitting an API endpoint. You're now on the hook for managing a data pipeline, a vector database, and the delicate dance between the retriever and the generator.
The core tradeoff is this: You gain massive improvements in accuracy and data freshness, but you take on the full responsibility of maintaining a high quality knowledge source and a more complex architecture.
It's a significant commitment, but for many use cases, the payoff is absolutely worth it. To make the choice clearer, let's lay out the pros and cons side by side.
RAG vs Standard LLMs: The Honest Tradeoffs
| Aspect | Standard LLM | Retrieval Augmented Generation (RAG) |
|---|---|---|
| Data Freshness | Knowledge is static, ending at its last training date. | Can access real time, up to the minute information. |
| Accuracy | Prone to "hallucinations" and making up facts. | Drastically reduces hallucinations by grounding answers in real data. |
| Source Transparency | Acts like a black box; you can't see where answers come from. | Can cite its sources, which builds user trust and makes debugging easier. |
| Complexity | Simple to get started, often just a single API call. | Requires managing a data pipeline, vector database, and retrieval logic. |
| Data Dependency | Relies solely on its internal, pre trained knowledge. | Performance is completely dependent on the quality of your external data. |
Ultimately, a standard LLM is faster to implement but leaves you at the mercy of its built in knowledge and its tendency to invent things. RAG puts more power—and more responsibility—in your hands. You get control over the facts, but you also have to own the entire data management lifecycle.
So, What's the Big Deal with RAG?
We've covered a lot of ground, from wrestling with those frustrating AI hallucinations to pulling back the curtain on how a Retrieval Augmented Generation system really works. Let's hit pause for a moment and boil it all down.
Think of this as your back of the napkin summary for what RAG is and why you should care.

The Core Idea
At its heart, RAG is a clever way to make LLMs more factual and trustworthy. It does this by giving a powerful generative model direct access to an external, up to date knowledge source before it even starts writing a response.
This simple but powerful architecture is really just a two step dance:
- The Retriever: This is your digital research assistant. Its only job is to dive into your data and pull out the most relevant snippets of information for a given query.
- The Generator: This is the LLM itself, which takes the facts handed to it by the Retriever and uses them to craft an accurate, context aware answer.
Why It's a Game Changer
The benefits here are clear and incredibly impactful. RAG drastically cuts down on model hallucinations, which is a massive win if you're trying to build reliable AI applications. It also means you can update your system's knowledge base on the fly without having to go through a costly and time consuming model retraining process.
But if you remember only one thing, make it this: the quality of your RAG system is 100% dependent on the quality of your data source. If you feed it garbage, it will give you well written, confident garbage in return.
This quick rundown should give you a solid foundation, ensuring you walk away with a clear picture of what Retrieval Augmented Generation really brings to the table.
Frequently Asked Questions About RAG
Even with a clear roadmap, jumping into a new architecture like Retrieval Augmented Generation always kicks up a few questions. I know I had a ton when I first started tinkering with it. Here are some of the most common ones I hear from developers and teams getting their hands dirty with RAG.
Can RAG Work With Any Type of Data?
The short answer is yes, but there's a huge asterisk attached. RAG is incredibly flexible and can chew on anything from PDFs and text files to database records and even transcribed audio.
The real bottleneck isn't the file format; it's the quality and structure of the data itself. For RAG to work its magic, your source information has to be clean, well organized, and accurate. Think of it this way: if your documents are a chaotic mess, your retriever is just going to pull back garbage, no matter how sophisticated your LLM is. Garbage in, garbage out.
Is Fine Tuning a Model Better Than Using RAG?
This is a fantastic question because it gets right to the heart of AI strategy. The thing is, fine tuning and RAG aren't competitors. They're different tools for completely different jobs, and they often work best together.
- Fine tuning is like teaching a model a new skill or giving it a specific personality. You might fine tune an LLM to adopt your company's brand voice or to understand the specific jargon of legal contracts. It fundamentally alters the model's behavior.
- RAG is all about giving a model access to fresh knowledge. It doesn't change the LLM itself, but it arms it with up to the minute facts and context it can use to build an answer.
Many of the most powerful AI systems out there actually use both. They might lean on a fine tuned model to get the tone just right, and then use RAG to make sure the information it provides is current and factually sound. It's not an either/or decision.
How Much Does It Cost to Run a RAG System?
I know this is a frustrating answer, but the cost can vary wildly. It all boils down to the scale of your operation.
The three main cost drivers you need to watch are:
- Vector Database: Storing and querying millions of document embeddings isn't free. As your knowledge base grows, so does this bill.
- Embedding Model API Calls: Every single piece of content you feed into your system—every document, every paragraph—has to be converted into an embedding. This usually means an API call you have to pay for.
- LLM API Calls: This is often the big one. Each time a user asks a question that triggers the full RAG pipeline, it results in a call to the generative model, which is typically the most significant ongoing expense.
My advice? Start small. A proof of concept with a limited dataset can be built for next to nothing, letting you prove the value of the approach before you start scaling things up.
Building production grade AI systems with a robust, scalable architecture is exactly what I help startups do. If you're exploring how to implement systems like this and need an expert to guide your technical strategy, build your MVP, or strengthen your engineering foundations, I'd love to connect. Learn more about my consulting work at my personal site, Kuldeep Pisda, at https://kdpisda.in.
Subscribe to our newsletter.
Become a subscriber receive the latest updates in your inbox.
Member discussion